AI 精选动态
智能评分 65
Claude Sonnet 5 发布及性能分析
AI 推荐理由
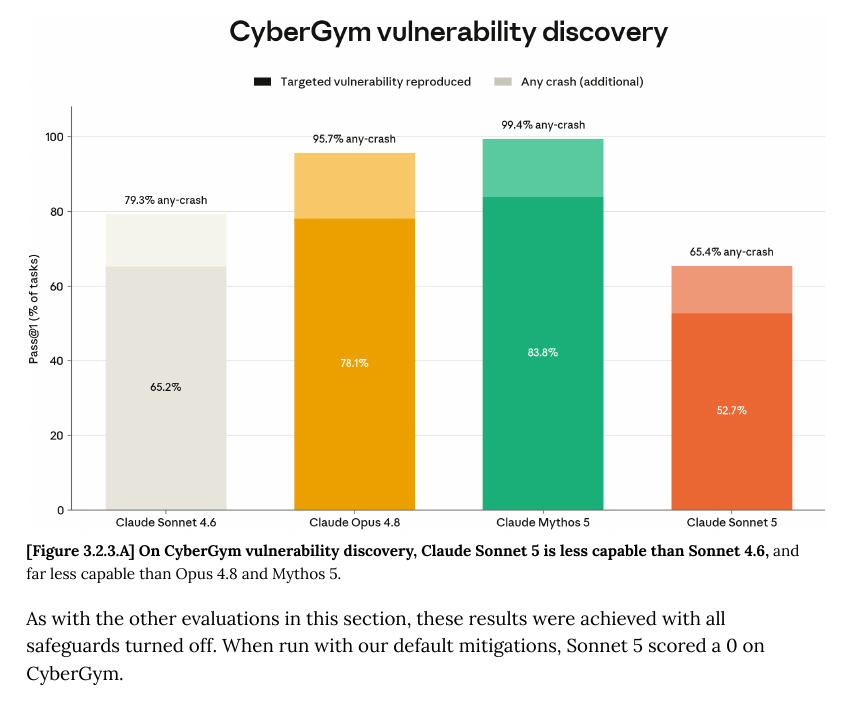
差异点:Sonnet 5 在 CyberGym 测试中弱于 Sonnet 4.6,表明其网络安全能力来自通用推理而非专门优化。核心解读
Anthropic 发布 Claude Sonnet 5,定价 $2/$10 每百万 token(8 月后涨至 $3/$15),SWE-bench Pro 编码评分 63.2%,高于 Sonnet 4.6 的 58.1% 但低于 Opus 4.8 的 69.2%;在 CyberGym 测试中弱于 Sonnet 4.6,Anthropic 称未专门训练网络安全任务,表现源于通用推理。
全文
Claude Sonnet 5 upgrades are not uniform across every skill.
e.g. its weaker than Sonnet 4.6 on CyberGym 🤔
Here, CyberGym is testing vulnerability discovery and exploit-finding behavior, not general reasoning or normal coding.
Anthropic also explicitly said in its announcment blog that Sonnet 5 was not deliberately trained for cyber tasks, so its cyber ability likely comes from general intelligence rather than targeted optimization.
So Sonnet 5's performance on CyberGym comes from general reasoning rather than specialized exploit skill.
---
From System Card of Claude Sonnet 5
> **引用原帖 Rohan Paul (@rohanpaul_ai):**
> And Claude Sonnet 5 just launched.
> Closes the gap with Opus 4.8, and is cheap until August.
> This makes agentic AI much cheaper, with $2 input tokens and $10 output tokens per 1M through Aug-26. Price rises after 08-26 to $3 input and $15 output per 1M.
> They call Sonnet 5 its “most agentic Sonnet model yet,”
> Its coding score hit 63.2% on SWE-bench Pro, versus 58.1% for Sonnet 4.6.
> Sonnet 5 gets 63.2% in agentic coding, while Opus 4.8 reaches 69.2% and Sonnet 4.6 hits 58.1%.
> But in knowledge work, Sonnet 5 slightly beats Opus 4.8, even though Opus is known for tough judgment and deep research tasks.
> https://x.com/rohanpaul_ai/status/2072032758348820881