AI 精选动态
智能评分 75
Introducing LongCat-2.0 🐱
AI 推荐理由
全流程国产算力和自研高阶算子技术凸显其MoE模型的闭环能力,多项SWE基准超越GPT‑5.5,建议深入阅读技术博客。核心解读
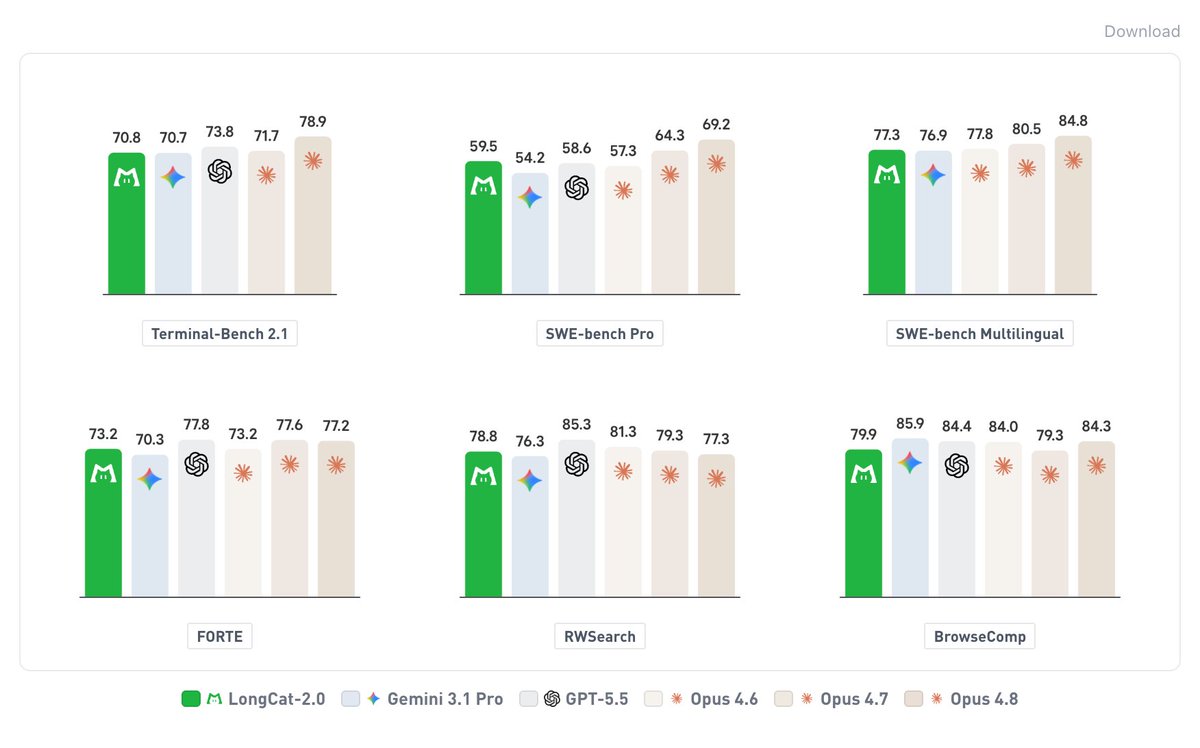
Meituan发布LongCat-2.0,1.6万亿参数MoE架构,约480亿激活参数,上下文窗口扩展至1M,训练使用5-6万块国产加速卡,实现训练及推理全流程不依赖英伟达;采用N-gram Embedding、稀疏注意力+跨层索引、自研底层算子(确定性FAG、Scatter重写)等技术;基准性能方面,Terminal‑Bench 2.1得70.8,SWE‑bench Pro 59.5(优于GPT‑5.5的58.6)、SWE‑bench Multilingual 77.3等,并强调与DeepSeek V4参数规模接近但路径不同,LongCat更聚焦国产化全链路。
全文
美团发布 LongCat-2.0 了,1.6T 参数 MoE 架构,激活参数 48B,上下文窗口 1M(最大输出 128K),采用 5-6 万张中国国产加速卡训练,训练推理全程零英伟达依赖。
三项关键技术
1. N-gram Embedding:参数前移 embedding 层,减 MoE 路由与通信开销
2. 稀疏注意力 + 跨层索引:支撑 1M 上下文,控制计算成本
3. 底层算子自研:确定性 FAG、Scatter 重写等,弥补国产芯片生态短板
能力定位
Agent + Coding 优先,非通用对话。Preview 在 OpenRouter 开发者调用量居前,Claude Code / Hermes 生态采用度高。
与 DeepSeek V4 的差异
参数量级相近(1.6T / ~48B / 1M),路径不同:DeepSeek 开源 + 双栈适配;LongCat 强调训推全链路国产化。
> **引用原帖 Meituan LongCat (@Meituan_LongCat):**
> Introducing LongCat-2.0 🐱
> 1.6T parameters · MoE with ~48B active · 1M context
> The full model behind Owl Alpha on @OpenRouter — now available.
> Built for agentic coding from the ground up:
> ◆ LongCat Sparse Attention (LSA) — scales efficiently for 1M-context tokens
> ◆ Zero-Compute Experts — dynamic activation 33B–56B per token, zero wasted compute
> ◆ MOPD — three specialized expert groups (Agent / Reasoning / Interaction), gate-routed per task
> How it stacks up:
> → Terminal-Bench 2.1: 70.8
> → SWE-bench Pro: 59.5 (GPT-5.5: 58.6)
> → SWE-bench Multilingual: 77.3
> → FORTE: 73.2 · RWSearch: 78.8 · BrowseComp: 79.9
> 📖 Tech Blog: https://t.co/4KrjyKiDBn
> Try it across different scenarios 🧵👇
> https://x.com/Meituan_LongCat/status/2071783587205308721