AI 精选动态
智能评分 69
OpenAI GPT-5.6 系列模型预览发布
AI 推荐理由
本文披露了 GPT-5.6 系列的具体定价、Ultra 模式 subagent 协作在 Terminal-Bench 2.1 等基准上的量化增益(Ultra 比 Sol 高 3.1 个百分点),以及 Terra 成本减半性能相当的关键对比数据。核心解读
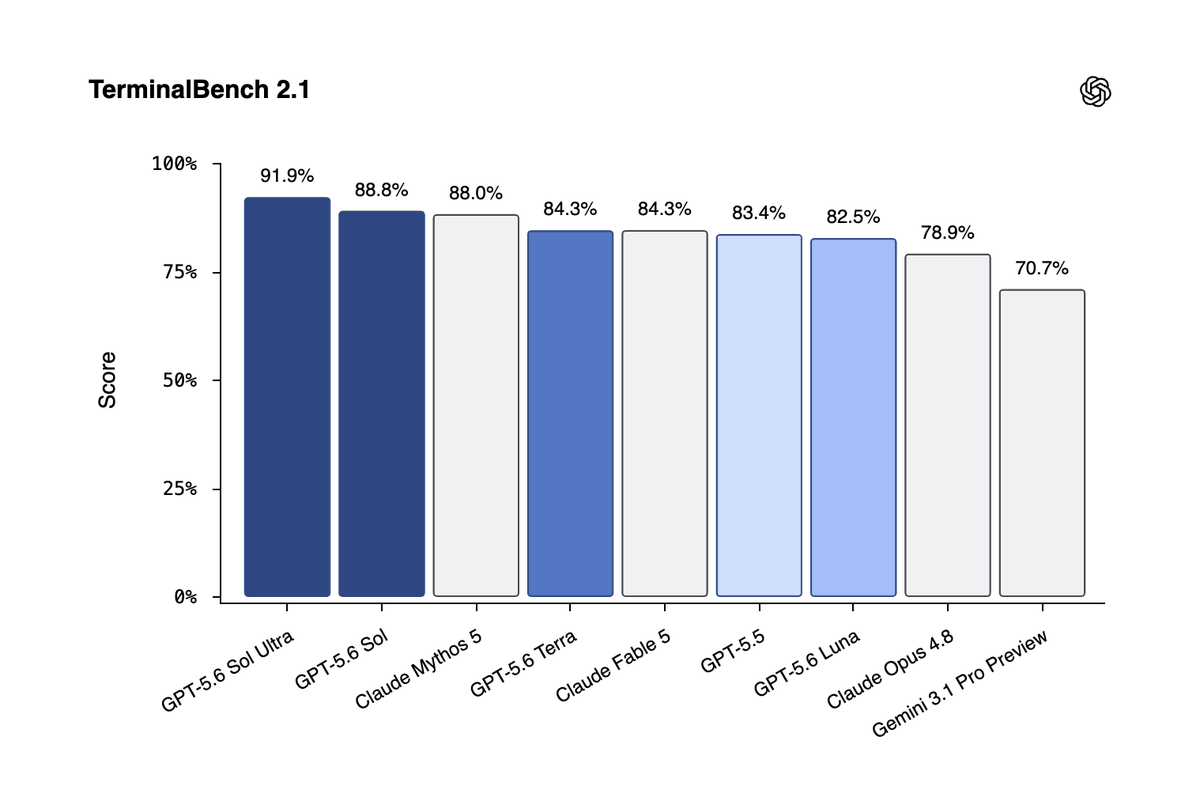
OpenAI 发布 GPT-5.6 系列模型预览,包括旗舰 Sol($5/$30)、均衡 Terra($2.5/$15)和轻量 Luna($1/$6),并引入 Ultra 模式通过 subagents 实现多 Agent 协作。Terminal-Bench 2.1 上 Sol Ultra 达 91.9%,Sol 88.8%;GeneBench 上 Sol 优于 GPT-5.5 且 token 更少;ExploitBench 上 Sol 用约 1/3 输出 token 与 Mythos Preview 竞争;Terra 性能与 GPT-5.5 相当但成本减半。
全文
OpenAI GPT-5.6 系列模型预览发布
好消息是 Sol 很强!坏消息是目前只能小范围预览,要配合美国政府监管审查!A 厂求仁得仁,转身拖 O 厂下水,原来 A 厂的 AI 宪法,就是:都别活 😄
· Sol - 旗舰,最强能力 $5 / $30
· Terra - 均衡,日常主力 $2.50 / $15
· Luna - 轻量,最低成本 $1 / $6
Terra 性能与 GPT‑5.5 相当但成本减半;Luna 在最低价位仍保留较强能力。
新能力:从"单 Agent 推理"走向"多 Agent 协作"
两个值得注意的新机制:
· Max reasoning effort:给 Sol 更深的推理预算。
· Ultra mode:超越单 Agent,通过 subagents 协同加速复杂任务。
Ultra 模式是本文最实质的能力跃迁信号——它把模型能力从"单个推理体"扩展到"协调多个 subagent 的系统"。在 Terminal‑Bench 2.1(命令行工作流基准)上,Sol Ultra 达到 91.9%,Sol 88.8%,而 Ultra 与非 Ultra 的差距本身说明"subagent 调度"带来了可观增益。
三大领域基准:编码、生物、网络安全的"效率前沿"叙事
OpenAI 反复使用一个框架:性能—效率前沿(performance-efficiency frontier),即不只比分数,更比"达到同等分数需要多少 token"。
· 编码:Terminal‑Bench 2.1 新 SOTA。
· 生物学:GeneBench v1(长程基因组与定量生物学分析),Sol 比 GPT‑5.5 分数更高且 token 更少。
· 网络安全:
· ExploitBench:Sol 用约 1/3 的输出 token 即可与 Mythos Preview 竞争。
· ExploitGym(UC Berkeley 联合前沿实验室):三档模型随推理增强,能力同步提升。
> **引用原帖 OpenAI (@OpenAI):**
> Introducing a limited preview of GPT-5.6 Sol, our next generation frontier model, as well as GPT-5.6 Terra, a balanced model for efficient, everyday work, and GPT-5.6 Luna, a fast and affordable model for high-volume work.
> https://t.co/OoM83SyISN
> https://x.com/OpenAI/status/2070555272230384038