AI 精选动态
智能评分 60
Optimizing Ling-2.6-1T on TPU with SGLang-JAX: Hiding MoE Data Movement Behind Compute with One Pallas Kernel
AI 推荐理由
文章详细披露了针对1T参数MoE模型在TPU上的具体优化手段(如Fused MoE V2、混合内存池),对从事大模型推理优化的从业者有直接参考价值,值得点开原文了解实现细节。核心解读
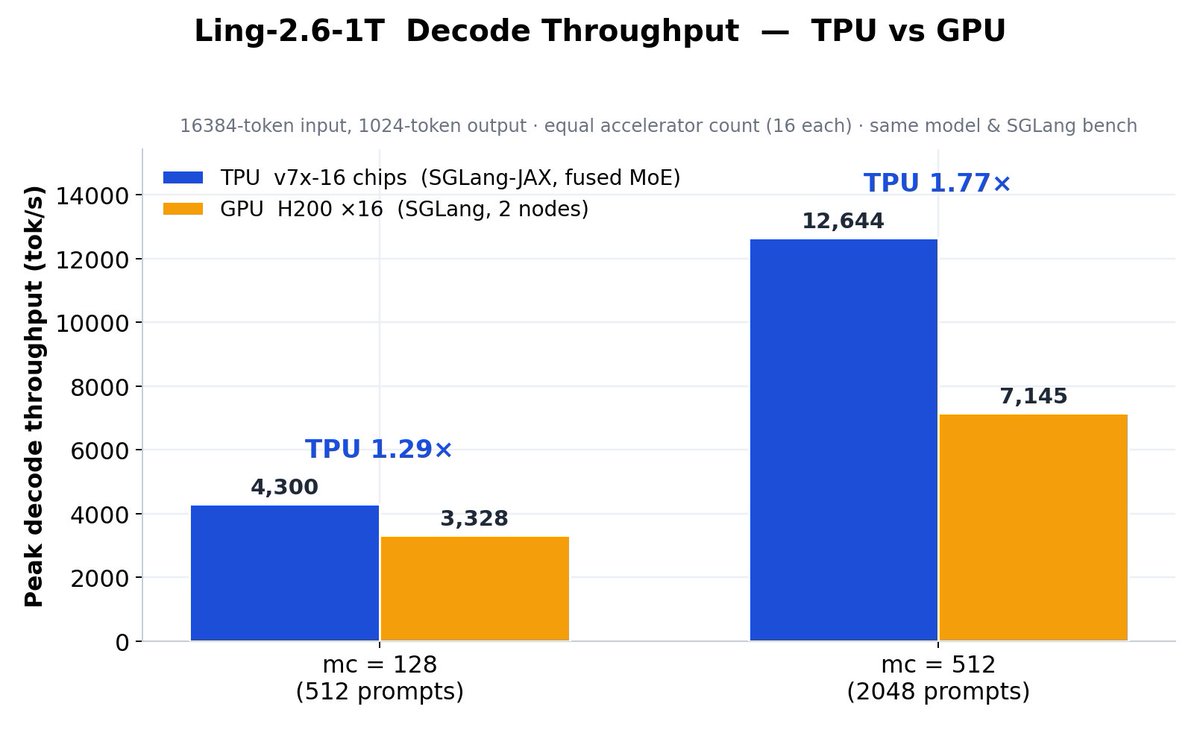
LMSYS Org联合inclusionAI发布博客,介绍在TPU v7x上使用SGLang-JAX优化Ling-2.6-1T(1T参数混合MoE模型)的服务。通过Fused MoE V2实现MoE prefill降低53%,并采用混合内存池、GLA线性注意力等优化。
全文
Ant Ling (@AntLingAGI) 转发了 LMSYS Org (@lmsysorg) 的帖子:
🚀 Our new blog: Optimizing Ling-2.6-1T on TPU with SGLang-JAX: Hiding MoE Data Movement Behind Compute with One Pallas Kernel
Ling-2.6-1T, a 1T hybrid MoE model, now serves on TPU v7x with SGLang-JAX. The SGLang-JAX team worked together with @inclusionAI on two fronts: upgrading the fused MoE kernel for deeper compute/comms overlap, and bringing up the full hybrid backbone.
1️⃣ Fused MoE V2: keeps tokens + accumulators VMEM-resident and double-buffers expert weights, hiding routing & prefetch behind compute → MoE prefill −53%
2️⃣ Hybrid memory pools: per-token MLA KV for 10 full-attn layers + per-request recurrent state for 70 GLA layers
3️⃣ GLA linear attention via chunk-wise parallel prefill
4️⃣ Single-controller DP keeps grouped RMSNorm chip-local, no per-layer cross-chip reduce